
Alarm Management:
Increasing Relevance, Improving Usability
Technical
Paper
Presented by:
Frost & Sullivan

Abstract
The proliferation of alarms has ultimately been self-defeating in its outcome – higher clutters of alarm data, large numbers of irrelevant and frequently-presenting nuisance alarms, reduced visibility of shelved and permanently suppressed alarms, ineffective correlation between alarm and process data, and compromised plant and operator safety. The implementation of an effective alarm management program involves creating a comprehensive and consistent alarm philosophy document, collecting and analyzing alarm data for rationalization and system improvements, monitoring and controlling the system on an ongoing basis and sharing alarm analytics with relevant stakeholders.
Contacts
support@citect.com
Lessons from a disaster
1:20 p.m. 23rd March 2005 - An explosion at the third-largest oil refinery in the United States, the BP Texas City Refinery, leaves 15 people killed and 180 injured.
When a distillation tower was unknowingly overfilled, extreme pressure resulted in the release of flammable hydrocarbon which then caused the massive explosion.
Several factors contributed to this disaster which resulted in a financial loss of US$1.5 billion. However, the Final Investigation Report of the incident, released in March 2007 by the US Chemical Safety and Hazard Investigation Board, highlighted lapses in alarm management that were critical:
“The tower’s high level alarm set-point was exceeded 65 times during the last 19 startups, with more than 50 hours of operating time with the high level alarm activated”.
“The redundant high level alarm (for the distillation tower) did not activate. When the....tower was filled beyond the set points of both alarms...in the early morning on March 23, 2005, only one alarm was activated. The high level alarm was triggered at 3:09 a.m. The redundant hardwired high level alarm never sounded”.
“The (redundant high level) alarm’s set-point was not known to operations personnel or provided in the procedure, control data, or training materials”.
“A functionality check of all alarms and instruments was also required prior to startup, but these checks were not completed”.
“Tower pressure alarm set-points were frequently exceeded, yet the procedure did not address all the reasons this might happen and the steps operators should take in response”.
Companies the world over are looking at these findings to understand not only how best to prevent such disasters from happening on their watch, but also to reassess their entire safety and risk management approach and specifically revisit their alarm management approach and practices.
Alarm systems have been an intrinsic part of plant safety management for a long time. They play a critical role in alerting operators to a change in operations at a process plant, inform operators about the nature of the change and guide operators to implement corrective action.
Poor alarm management results in:
- Increased downtime (when source alarms cannot cut through the clutter, then real problems are ignored for too long; resulting in process breakdowns). This translates into lost production as well as increased operator costs through overtime, and higher lifecycle cost of equipment through increased maintenance costs
- Reduced plant productivity. When operators do not read early the signs of a developing problem, their response to alarm floods (large numbers of alarms annunciated at the time of process upset) typically takes the form of stabilizing the process through reducing the rate of throughput
- Reduced quality (when alarm systems fail to alert operators to corrective action at the right time, off-spec product has to be contended with)
- Reduced operator effectiveness, higher operator stress levels and increased operator staffing costs
- In the worst-case scenario, alarm-related confusion can result in or aggravate serious industrial accidents
- Increased insurance premiums on plant equipment or fines incurred by not meeting regulatory requirements
Too much of a good thing
However, despite their obvious significance, alarms have become yet another case of having “too much of a good thing”; making less functional what was once an effective safety and productivity improvement system.
How did this come about?
When control systems became mainstream, they also brought down the cost of alarms; thus increasing the proliferation of such alarms. After all, engineers did not have a strong cost disincentive to configuring excessive numbers of alarms.
With this excess came reduced visibility of urgent and underlying problems, increased clutter that operators had to deal with and longer response time to undertaking appropriate corrective action.
Indisputable evidence of this came from an even earlier industrial disaster than that at the BP Texas City Refinery – the July 24th, 1994 explosion at the Texaco Refinery in Milford Haven, Wales. According to the Health and Safety Executive (HSE) that investigated the incident, “the flood of alarms greatly decreased the chances of the operators restoring control in the plant.” Not surprising when it was determined that during the incident, alarms were presented at the rate of 20-30 per minute; with operators contending with 275 alarms in the final 11 minutes. As HSE put it “warnings of the developing problems were lost in the plethora of instrument alarms triggered in the control room, many of which were unnecessary and registering with increasing frequency, so operators were unable to appreciate what was actually happening.”
Going back further in time, the meltdown at the Three Mile Island Unit 2 nuclear power plant near Middletown, Pennsylvania (28th March 1978) also saw a similar alarm flood (110 alarms presented during the incident, preventing operators from understanding the real problem for 2.5 hours).
Adopting a systematic approach
To help organizations move away from the ad hoc approach of the past and adopt a more systematic and rational approach to alarm management, in 1999 the Engineering Equipment and Materials Users Association (EEMUA) released 191 ‘Alarm Systems: A Guide to Design, Management and Procurement’.
This guide has rightly become the global reference point for alarm management. Its second edition – available from June 2007 – significantly updates and builds on the first edition.
Designers and operators have much to gain from using EEMUA 191 when undertaking improvement of their existing alarm systems or launching into a new alarm management program.
The essentials
To understand how best to improve an existing alarm system or introduce a new alarm management program, it is useful to approach the task using the steps outlined in the well-known Six Sigma sequence.
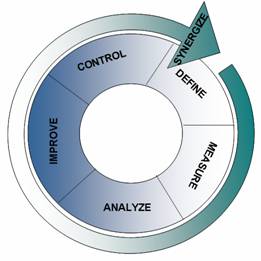
Define
Successful alarm management is based on a comprehensive and consistent alarm philosophy document that defines:
- Business objectives to be met
- Needs and requirements of the users of the alarm system
- Alarm system design principles
- Compliance parameters
- Roles and responsibilities
- Criteria for alarm generation, setting, prioritization and presentation
- Management of Change (MOC) (for example, tracking authorized and unauthorized changes to alarm settings or alarm suppression or shelving)
- Training / maintenance parameters
- Escalation guidelines (moving from normal status mode where operators are trying to keep the process within the ‘safe envelope’ to emergency/ disaster management)
Measure
Typically, with thousands of alarms per site, a ‘stock take’ of the existing process, alarms and trends is critical before any changes are implemented. But while engineers and designers appreciate the benefits of such an exercise, the task – by virtue of its scale – can be quite daunting.
This is where certain plant Historians (central data repositories that gather, historize, archive and distribute plant data) can simplify the task. For example, CitectSCADA Reports, the plant-wide reporting solution from Citect, is capable of accurately recording all alarm data and tag values at high speed. Such a tool can help engineers and operators gather and organize alarm data from across the entire site.
Analyze
If gathering data from thousands of alarms appears daunting, then analyzing such data to derive useful insight can be even more formidable an undertaking.
Some plant Historians provide assistance with this by helping engineers and operators with the following:
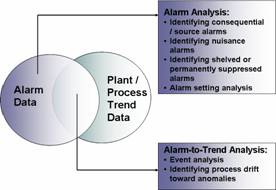
- Event analysis: Pulling up all alarms that occurred at a given point in time, be they basic process alarms or aggregated alarms or even critical safety-related alarms.
- Alarm and event archiving: Historizing all alarms and events for long term analysis.
- Alarm analysis, which
includes:
- Identifying consequential/source alarms around which other alarms are triggered
- Identifying nuisance alarms such as stale alarms (that remain present for extended periods of time), chattering alarms (that go in and out of alarm mode in a short span of time), or duplicate alarms (that persistently occur within a short period of time of another alarm). Pareto analysis can help rank nuisance alarms by frequency; to help detect the so called “bad actors”
- Identifying shelved alarms (temporarily suppressed) or permanently suppressed alarms (that are prevented from appearing on the operator’s screen)
- Alarm setting analysis by the state/mode of operation of the plant
The fruits of such analysis are many:
Cutting through the clutter: EEMUA 191 suggests that 150 alarms per day (one every 10 minutes) presented to an operator is "very likely to be acceptable" and 300 alarms per day (an alarm every 5 minutes) is considered "manageable". In reality it is not unusual to record tens of thousands of alarms per operator per day, which makes such a system self-defeating. Identifying nuisance alarms helps to eliminate unnecessary or ineffective alarms, thus bringing the number of alarms per operator to a more manageable ratio.
To do this, clear justification for each alarm is required. An alarm's reason for being should be related to a specific problem or abnormal situation and also to a specific and defined operator response. If there is no problem or if the alarm is not intended to elicit specific operator action, then its legitimacy should be questioned. A process indicator or alert does not automatically equate to an alarm.
|
Average Alarm Rate |
|
|
Very likely acceptable |
<1 per 10 min |
|
Manageable |
< 2 per 10 min |
|
Likely over-demanding |
> 5 per 10 min |
|
Very likely unacceptable |
> 10 per 10 min |
|
Peak Alarm Rate |
|
|
Should be manageable |
<10 per 10 min |
|
Hard to Cope |
20 to 100 per 10 min |
|
Definitely Excessive |
<100 per 10 min |
Source: EEMUA 191
Under the carpet: Analyzing shelved alarms can help highlight potential reductions in alarm numbers there as well. More importantly, by looking at how long important alarms have been shelved or permanently suppressed, operator practices can be corrected (having shelved an alarm, there is no guarantee that the operator remembers to go back to reactivate it).
The heart of the matter: Identifying root alarms or consequential alarms helps ensure that in an alarm flood, prioritization models have been configured such that the consequential alarm does not get lost or remain unnoticed.
For consequential alarm and event analysis, most Historians would compare one set of alarm data with another set of alarm data (depending on the query placed). However, what is even more useful is to be able to compare alarm data with plant/process trend data.
This is significant because alarms – being reactive in function – cannot anticipate by themselves any process drift towards an abnormality which could eventually lead to breakdown or process failure. Co-relating alarm data with trend information can help throw up such insight.
It can also help in fine-tuning alarm settings and in linking alarm spikes to specific process conditions (startups, shutdowns, change in process set points such as tank levels, pressure, temperature levels etc), changes in instrumentation or new or changed control system configurations. In addition, it is by analyzing operator response to alarms (and not simply focusing only on alarm data) that poor alarm system design is identified.
CitectSCADA Reports offers such an option, since it historizes both alarms and plant process trends. This way, alarm and event data can be co-related to trend data from the plant to throw up anomalies or areas for alarm rationalization or even assist in incident reviews.
Source: Frost & Sullivan
Improve
The analysis stage seeks to assess each alarm from the standpoint of the alarm philosophy of the organization and typically leads to certain specific improvements:
- Reduction in needless alarms
- Recalibration of alarm parameters where necessary (such as action, set point, detection time etc)
- Bringing in consistency in alarm settings where desirable
- Prioritization of alarms where required
- Reorganization of the presentation of alarms if needed (to ensure relevance to operator, visibility etc)
This process of alarm rationalization and system improvement is clearly a laborious, expensive and disruptive effort, but the support of robust alarm analysis can help simplify this step.
While implementing this step, the temptation is to focus only on the “bad actors” i.e. the low-hanging fruit. This, as an initial focus, is appropriate – given that it provides immediate relief to an overloaded system. However, alarm floods (which involve many more alarms presenting than just the top 5 or 10 most frequent alarms) can be minimized only by undertaking a total rationalization exercise of all alarms in the system.
EEMUA Recommendation on split of total alarms by priority assignment levels
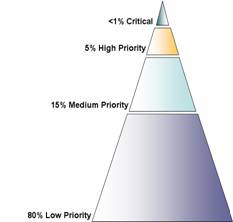
Source: EEMUA 191
Control
Successful alarm management rests on what tools are used to ensure that the KPIs set out are achieved so that gains are sustained. This also involves creation of appropriate training material for new personnel who get involved, procedures and manuals for management of change (MOC) and ongoing review of analysis findings from the Historian. The operative word here is ‘ongoing’. This is because new nuisance alarms have the habit of appearing surreptitiously (probably the result of instrumentation failure, changes to plant equipment and process conditions, lack of adherence to MOC procedures, or inadequate justification for new alarm additions).
Synergize
In a “learning organization”, the fruit of analysis of the alarm system is shared with other stakeholders who are not necessarily on the plant floor. This is also helpful when plant engineers need to keep senior management informed of progress in alarm system improvements and to justify future investments in the alarm system to senior management. With CitectSCADA Reports v4 and above, which uses an embedded Microsoft SQL Server 2005, operators, engineers and management will be dealing with an industry-standard data storage and exchange tool. Reports can be delivered in a variety of formats (such as pdfs for regulatory reports, Excel spread sheets that allow any user to immediately extract data for further analysis or web pages that can be integrated with other business systems in the organization).
Citect also offers consulting services direct and through its Professional Services and System Integration partners, to add further value by guiding customers through the process of developing their alarm philosophy and rationalizing their alarms.
The next level
To ascertain clearly what is the extent of improvement required in an alarm system (gap analysis) or to measure improvements after a new alarm management program has been initiated, it is useful to compare the system with industry best practice.
To undertake this, benchmarking tools such as Citect’s Meta can prove useful. Meta enables comparison of KPIs across plants, divisions and countries; both within an organization or across an industry peer group.
Some alarm KPIs that could probably form the basis for such benchmarking include:
- Average number of alarms per hour
- Maximum number of alarms per hour
- Percentage of hours where there were >30 alarms per hour
- Operator response time
The ‘Human’ Dimension
In the final analysis, successful alarm management is not about the equipment or the alarm, but about people who impact and are impacted by the alarm system – operators, process and control engineers, maintenance personnel, shift supervisors, instrument and control system technicians, designers, safety officers, training staff and senior management.
To implement a successful alarm management program requires factoring in the different expectations and priorities as well as the differing levels of awareness and understanding among these diverse groups of stakeholders.
Tools that can help to
effectively share alarm analytics and the resulting insight across
these stakeholders in a simple, relevant, meaningful and
easy-to-understand format will help ensure that alarm management is
fed back the multi-level and multi-disciplinary input it requires
to validate it and keep it relevant to the business objectives and
the alarm philosophy of the organization. Tools that can take alarm
KPIs and benchmark them against industry best practice, could take
alarm management to the next level and provide the organization
alarm report cards that can directly result in improved
productivity, profitability and safety.
Disclaimer
Disclaimer of All
Warranties
SCHNEIDER ELECTRIC (AUSTRALIA) PTY LTD DISCLAIMS ANY AND ALL
WARRANTIES WITH RESPECT TO SCHNEIDER ELECTRIC (AUSTRALIA) PTY LTD
PRODUCTS AND THE RELATED DOCUMENTATION, WHETHER EXPRESS OR IMPLIED,
INCLUDING SPECIFICALLY THE IMPLIED WARRANTIES OF MERCHANTABILITY
AND FITNESS FOR A GENERAL OR PARTICULAR PURPOSE. CITECTSCADA AND
THE RELATED DOCUMENTATION ARE PROVIDED "AS IS," AND YOUR COMPANY
UNDERSTANDS THAT IT ASSUMES ALL RISKS OF THEIR USE, QUALITY, AND
PERFORMANCE.
Disclaimer of
Liability
YOUR COMPANY AGREES AND ACKNOWLEDGES THAT SCHNEIDER ELECTRIC
(AUSTRALIA) PTY LTD SHALL HAVE NO LIABILITY WHATSOEVER TO YOUR
COMPANY FOR ANY PROBLEMS IN OR CAUSED BY SCHNEIDER ELECTRIC
(AUSTRALIA) PTY LTD PRODUCTS OR THE RELATED DOCUMENTATION, WHETHER
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, OR CONSEQUENTIAL (INCLUDING
LOSS OF PROFITS).
Related Links
Attachments