Cascading and data reduction |
|
Manual -> Archiving -> General information -> Cascading and data reduction |
Cascading and data reduction |
|
Manual -> Archiving -> General information -> Cascading and data reduction |
The archiving is based on the principle of cascading archives i.e. the desired process variables are captured in an input archive and transferred into a following archive via summarizing functions.
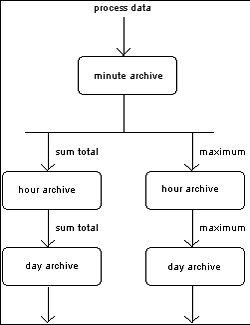
This process can be continued as often as desired. The summarising function is initiated at the ending of the archive cycle. Available as summarising functions over the archiving cycle per archive process variable are:
|
1 |
Sum |
|
2 |
Average |
|
3 |
Minimum |
|
4 |
Maximum |
In a project, several cascades can also work in parallel.
|
|
|
Strings cannot be compressed. |
Different types of archiving are distinguished. Available as a trigger for the entries into the archives are:
|
Cyclic |
Writing values to the archive is triggered by a fixly defined cycle. |
|
Event triggered |
Writing values to the archive is triggered by a defined bit variable. |
|
Spontaneous |
Writing values to the archive is triggered
by a value change of one of the linked variables, i.e. the number
of archives values depends on the frequency of change. |
There are several possibilities for the exporting of an archive cycle.
|
Database |
Ring store for each archive in which the defined number of archive cycles is held. Post processing of the archive data within the ring. On overflow of the ring store optionally discard archive or export to file. |
|
File export |
After closing of an archive cycle it is immediately exported to a file. |
|
The archive export i.e. the saving of archives to files with time filter, is done in standard file formats (ASCII, dBase, XML, SQL). The file names are issued independently from the system. The structure (YYMMDDhhmmsst/XML) encodes the export time with an identifier for archive, year, month, day, hour, minute and second. The file storage can be done both locally and also when integrated into a network on a file server: |
As the format of the archive files changed, at the start of the Runtime it is checked, if there are archive files (they are recognized by the file extension ARV) in the Runtime directory. After the confirmation the files are converted to the new format. This conversion is done for all projects, before the projects start.
The old archive files are deleted. We recommend backing up the files before.
Server and standby server do the conversion parallelly before the data alignment.